Future Vision Transport : Design an Autonomous Vehicle¶
Context¶
"Future Vision Transport" is a company building embedded computer vision systems for autonomous vehicles.
The goal here is to build a model able to classify each pixel of an image into one of the given categories of objects, and expose this model's API as a web service. This problem is known as "Semantic Segmentation" and is a challenge for the autonomous vehicle industry.
We will compare different models (varying architecture, augmentation method and image resizing) and their performances on the Cityscapes dataset. We will use AzureML and Azure App Service to deploy our models.
State of the art¶
In Computer Vision, the problem of Semanitc Segmentation is to classify each pixel of an image into one of the given categories of objects.
Deep Neural Network (DNN) models¶
The basic principle of DNNs for Semantic Segmentation is basically to :
- Down-sampling / Encoder : use Convolutional Neural Network (CNN) layers to extract features from the input image
- Up-sampling / Decoder : use fully connected layer to classify each pixel into one of the given categories of objects

Over the time, research teams have produced more sophisticated models with more layers, connections between layers and different convolution kernels in order to improve the prediction accuracy.
The major models are :
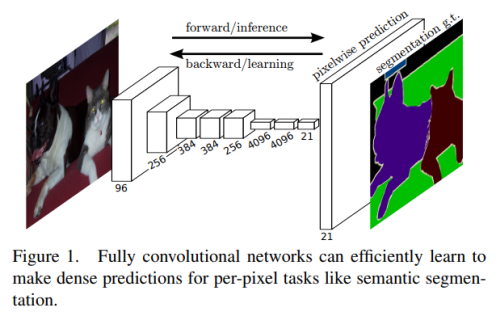
- FCN (2015) : Fully Convolutional Networks
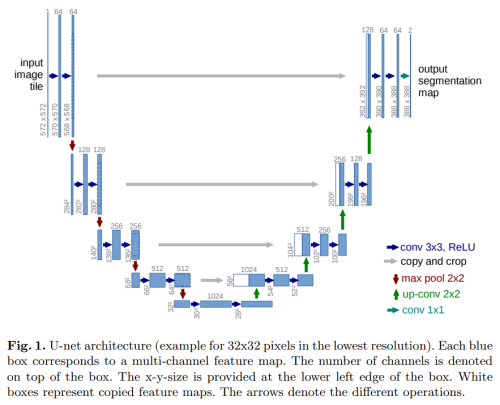
- U-Net (2015) : a deep neural network architecture with a U-shaped structure
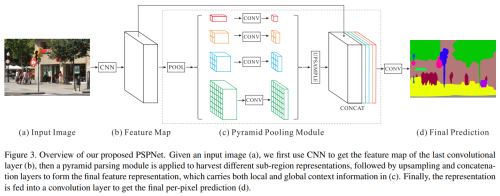
- PSPNet (2017) : Pyramid Scene Parsing Network - a deep neural network architecture with a pyramid structure
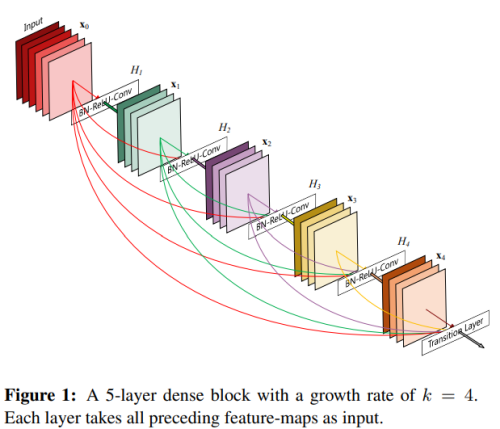
- DenseNet (2018) : Densely Connected Convolutional Networks - a deep neural network architecture with a densely connected structure
- DeepLabv3+ (2018) : an Encoder-Decoder architecture with Atrous Convolution
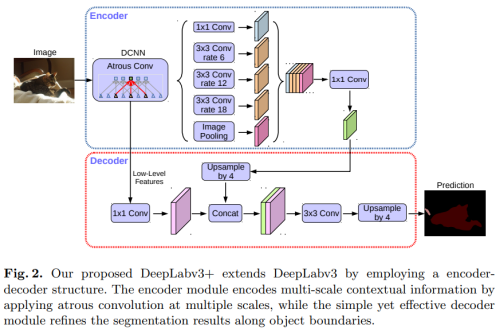
Results on the Cityscapes Dataset¶
The Cityscapes Dataset is a large dataset of images captured by a car dash camera in the city, with their corresponding labels.

Project modules¶
notebooks/:- train.ipynb : orchestration of the models training process in AzureML
- eval.ipynb : running the evaluation of the models in AzureML
- deploy.ipynb : orchestration of the models endpoint deployment process in AzureML
- predict.ipynb : orchestration of the models prediction tests process in AzureML
azureml/: contains the code deployed in AzureML training and prediction environments.
webapp/: contains the webapp deployed in Azure App Service.src/: contains the helpers functions and project specific code.
We will use the Python programming language, and present here the code and results in this Notebook JupyterLab file.
We will use the usual libraries for data exploration, modeling and visualisation :
- NumPy and Pandas : for maths (stats, algebra, ...) and large data manipulation
- Plotly : for interactive data visualization
We will also use libraries specific to the goals of this project :
- TensorFlow and Keras : for deep learning
- Image processing :
- Pillow : for image manipulation
- OpenCV : for image processing
- Albumentations : for image augmentation
















