AutoML model : max 1h training on CPU¶
In this version, we did not include DNN models in the AutoML process, because they require GPU resources.
This AutoML run is available in the AzureML Studio : automl_1h-cpu
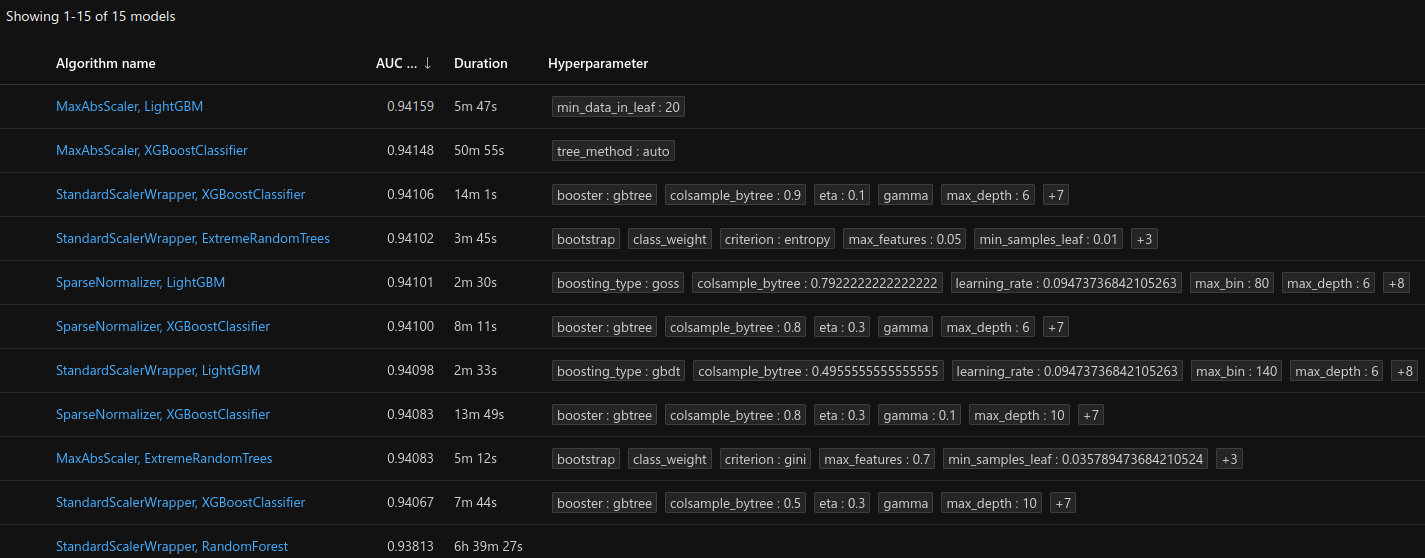
Here are the models that were trained in the AutoML process :
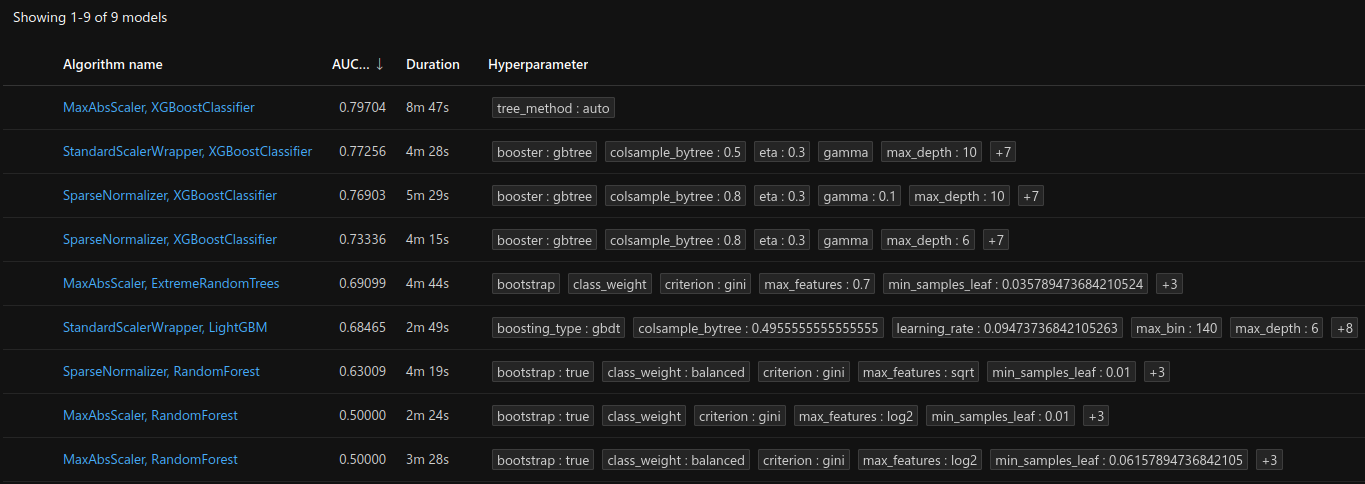
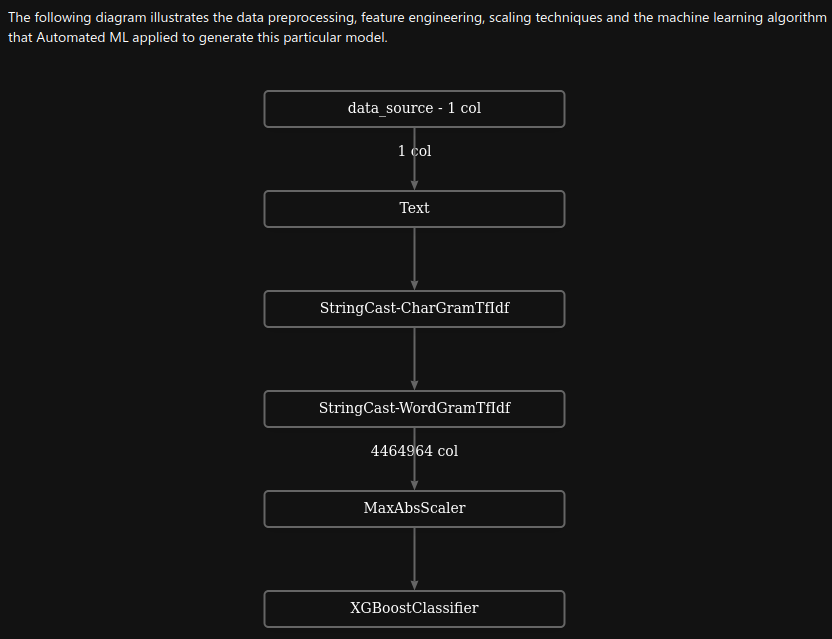
Best model¶
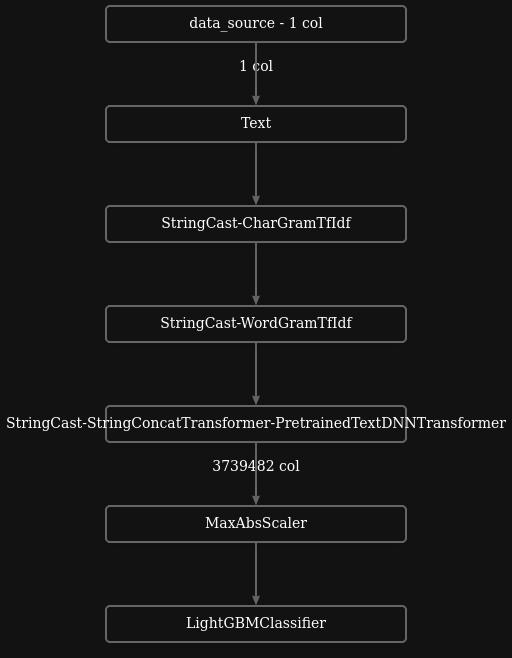
The best model is a XGBoostClassifier (wrapper for XGBClassifier) with MaxAbsScaler .
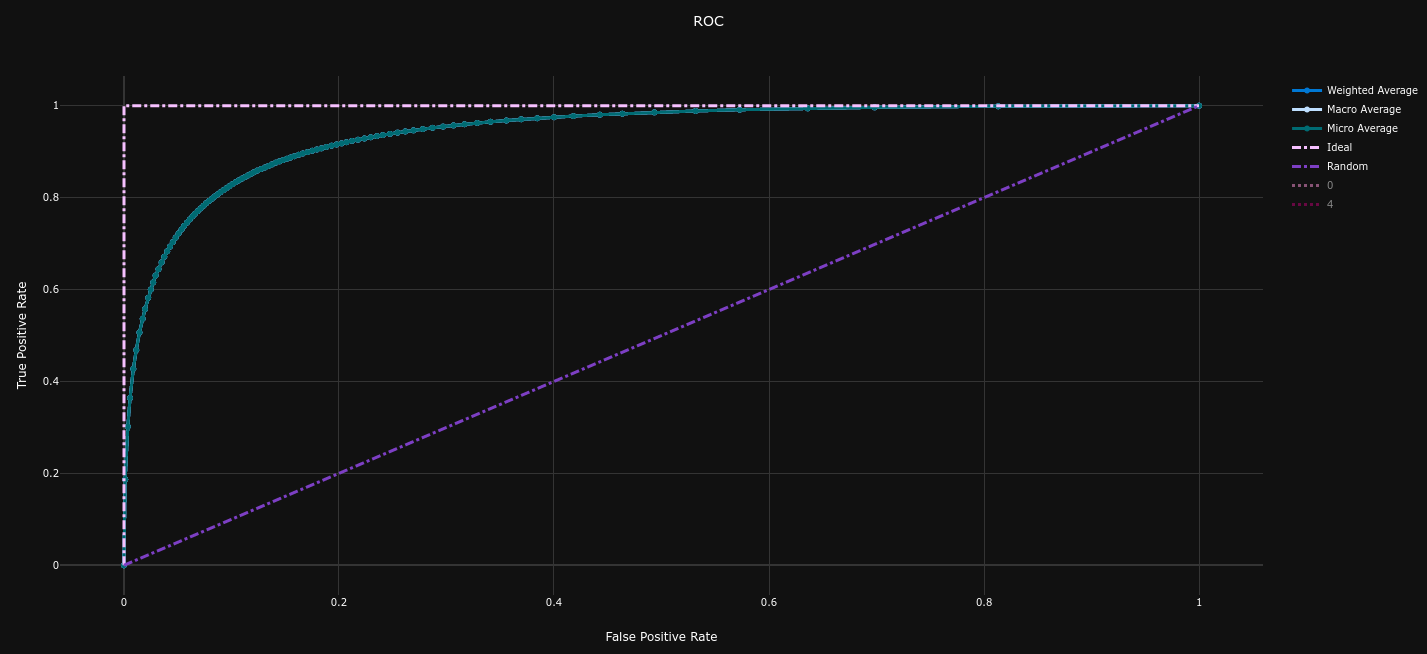
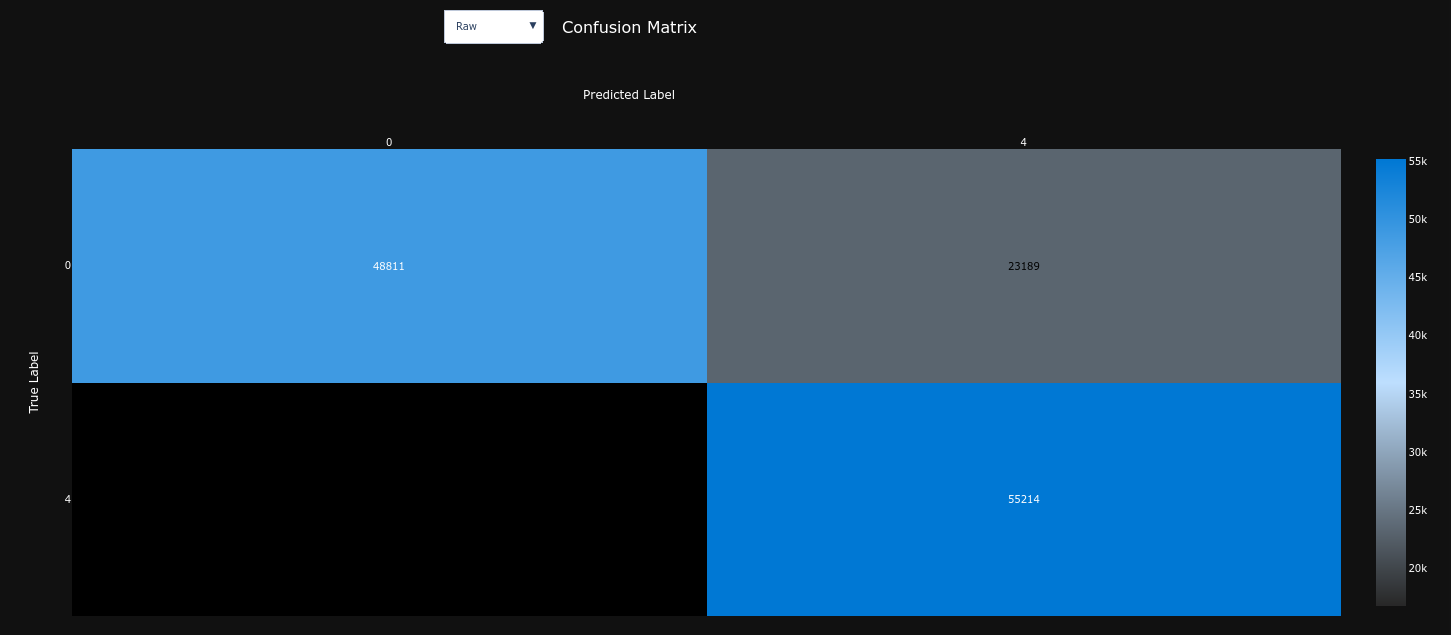
Results¶
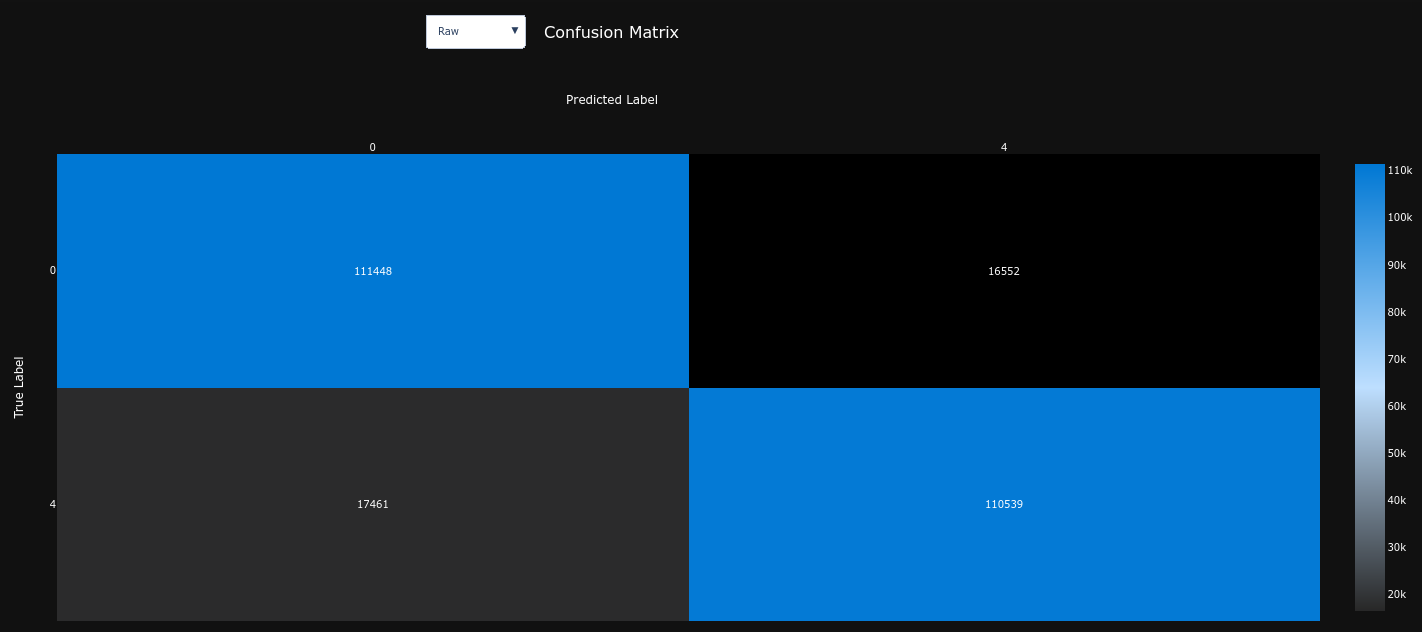
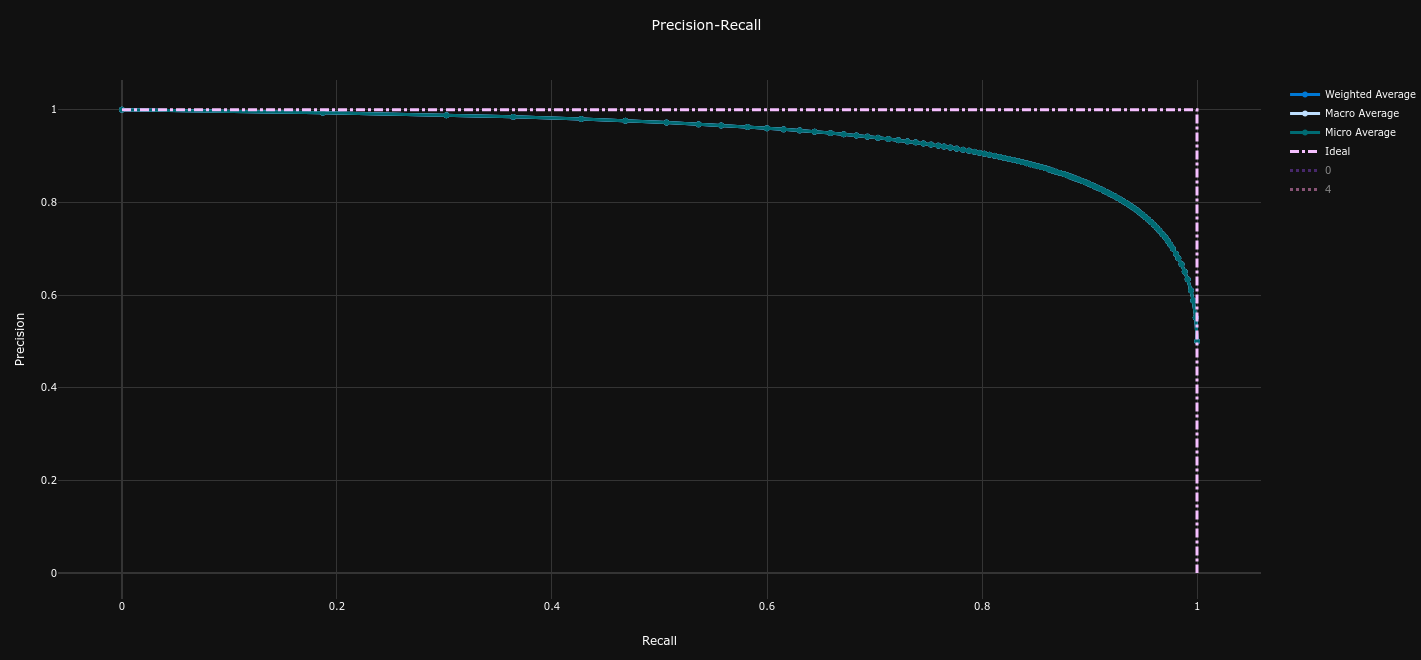
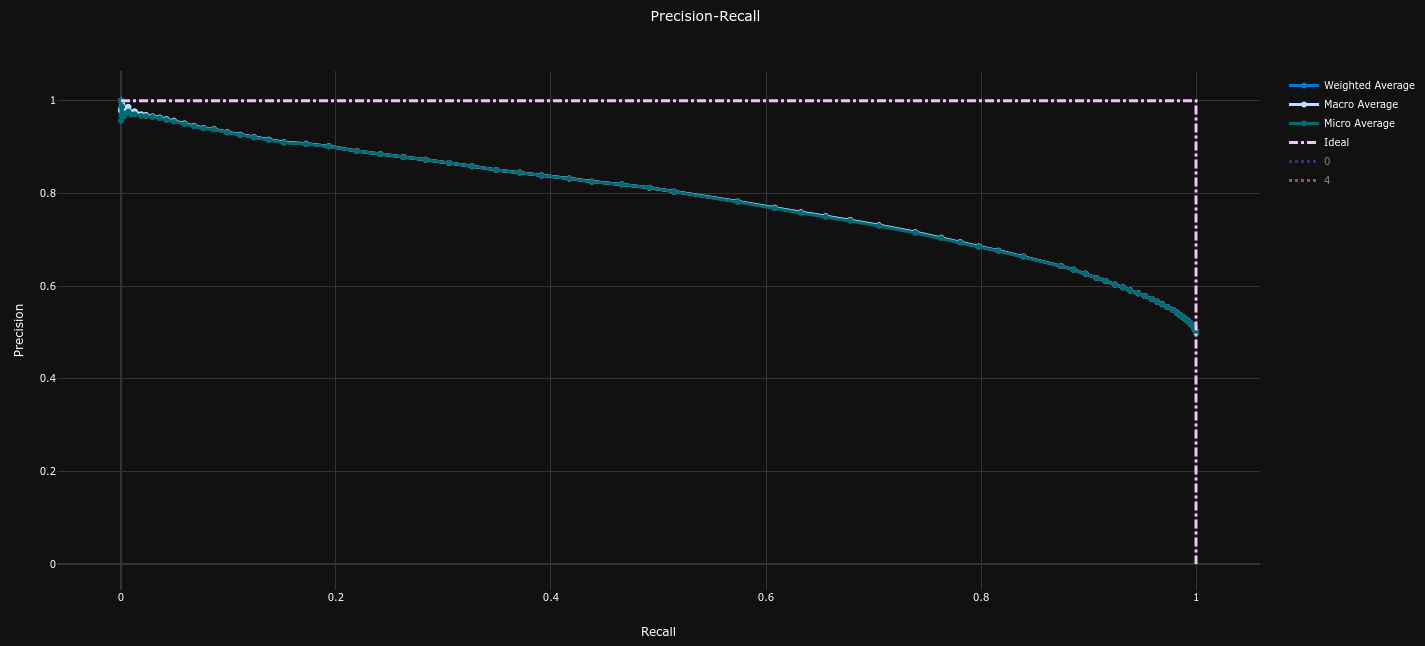
| Confusion Matrix | Precision Recall Curve (AP = 0.79) | ROC Curve (AUC = 0.80) |
|---|---|---|
 |
 |
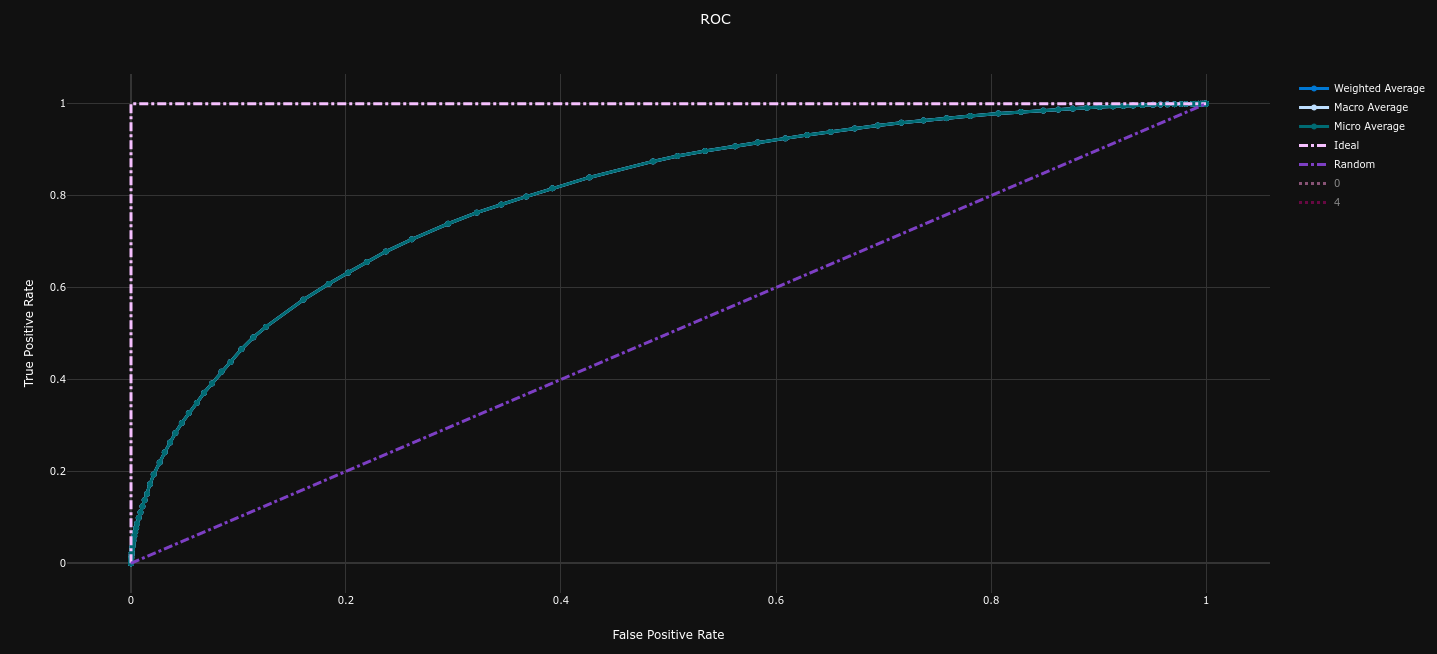 |
The performances on the dataset are quite better than our baseline model :
- Average Precision = 0.79 (baseline = 0.73 , +8.2%)
- ROC AUC = 0.80 (baseline = 0.74 , +8.1%)
Unlike our baseline model, this model is quite balanced, just slightly biased towards the POSITIVE class. It is much less biased than our baseline model : it predicted 9% (baseline = 35% , -74%) more POSITIVE (78403) messages than NEGATIVE (65597).